Democratizing AI Deployments: Announcing Cisco Foundation AI Quantized Model

Quantization is the process of converting a machine learning model’s weights and activations from high-precision (e.g., 32-bit floating point) to lower-precision formats such as 8-bit or 4-bit integers. This transformation drastically reduces the model’s memory and storage footprint as well as compute requirements, enabling faster inference and more efficient deployment on constrained hardware whether at the edge, in a private cloud, or in GPU-limited environments.
For large language models like Foundation-sec-8b, quantization is a key enabler of practical, real-world deployment. It allows security teams to integrate state-of-the-art AI into their workflows without the high cost or latency typically associated with full-precision models.
🚨 Why It Matters for Security Teams
Security teams often face stringent infrastructure, latency, and compliance constraints. Deploying quantized versions of Foundation-sec-8b allows them to:
- Run inference on CPUs or low-memory GPUs; an 8-bit quantization of our model can run locally on a standard MacBook Pro.
- Reduce operational costs without compromising detection performance.
- Integrate LLM-powered alert triage, threat hunting, and detection engineering into their pipelines with real-time responsiveness.
This aligns closely with the operational needs of modern security environments: high-speed response, low overhead, and flexibility in infrastructure choices.
✅ Quantized Performance Holds Up
In benchmarking across representative security tasks, the quantized model maintains comparable performance to the full-precision Foundation-sec-8b model. Below is a comparison across key evaluation benchmarks:
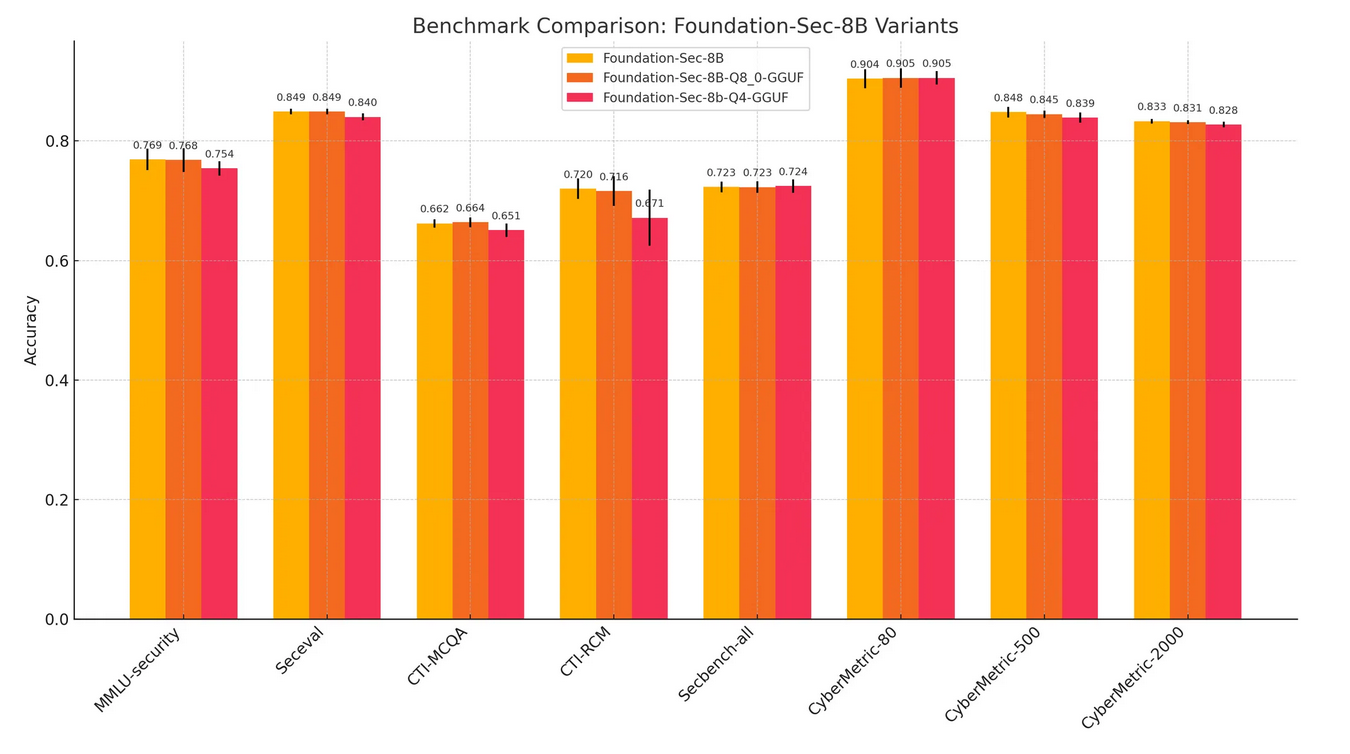
These results demonstrate that quantization delivers substantial efficiency gains with minimal loss in accuracy, making it a powerful lever for operationalizing LLMs in security-critical environments.
📦 Availability
Several community-generated quantized checkpoints of Foundation-sec-8b are already live on Hugging Face. In addition, the Foundation AI team is releasing both a 4-bit and 8-bit official, production-ready, quantized build ensuring:
- Consistency across downstream tasks
- Support for common deployment frameworks (e.g., ONNX, TensorRT, GGUF)
- Ongoing compatibility and updates
This gives security teams a low-friction, open-weight option that preserves the trust and transparency required for sensitive operational contexts.
Contributors: Alex Chen, Blaine Nelson, Paul Kassianik, Aman Priyansh, Dhruv Kedia, Amin Karbasi